With the advancement of the databases, requirement to access the data as fast as possible is increasing day by day. Not only this but the data is not restricted anymore from the standard business applications only and can be generated from a wide variety of sources. For example, now everyone has a phone and that phone is probably also connected to a home automation device. Two different devices but generating something common- data. With this rapid increase in the volume of the data, requirement to access it also has increased.
In the past, data , if cached in the buffer cache was considered to be accessed faster since it’s not going to be requiring a physical IO scan of the blocks from the hard drive. But buffer cache is like a heap. It contains a huge amount of data in the form of data buffers. And to access these buffers, you need to traverse through these buffers over (hash) chains over which these buffers are sort of hanging around. Of course, using a Hash table creation on the Data Block Address(es) of the buffers, search for a segment’s buffer is facilitated but it’s not possible for such mechanism to keep up with the ever increasing volumes of the data. In addition to this, there must be a way to access this buffered data from the buffer cache much quickly too.
But hold on, all what we have said so far is just about selecting the data. So, what’s the problem you may say? Well, just a small one- we can only select the data if we have inserted it in the first place. So if the selection of the data has to be faster, so should be the insertion as well.
Enter 18c’s MemOptimized Rowstore
Memoptimized rowstore is a new memory area in the SGA from 18c onwards which basically solves the issues that we have mentioned above. What it provides is Fast Ingest(intake) and Fast Lookup.
In this first part of two-part series, we shall understand how this feature works and enhances query execution i.e. Fast Lookup.
How Memoptimized Store works?
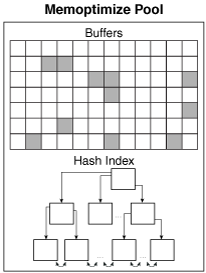
Memoptimized Rowstore is configured though a separate memory area called memoptimzed ;pool.
 – 1)
– 1)
This pool is configured by the parameter MEMOPTIMIZED_POOL_SIZE .
SQL> show parameter memopt
NAME TYPE VALUE
———————————— ———– ——————————
memoptimize_pool_size big integer 0
SQL>
In our database, currently this parameter is set to 0 which means there is no memory optimization happening for our table. If you are going to be setting this parameter, minimum values is 100MB.
Now what I have experienced while hearing or discussing this in the sessions that a lot of people understand that this a “new” buffer cache that’s there. If you thought like that too, it’s incorrect. Database buffer cache is still the same and functions just the same. Memoptimized Pool, though works with Buffer Cache but it’s a separate memory structure.
Memoptimized Pool creates two separates sections inside it- for storing the buffers and another which is going to be used to create an in-memory Hash Index.
And that’s why, as shown in the picture, memoptimized pool is divided into two sections- two distinct sections of the pool. The buffers area constitutes 75% of the total size of the memotipized pool and the remaining size is held up by the in-Memory Hash index.
When does this area within the Memoptimized Pool gets uploaded with the buffers of the table? Well, when we are going to upload the table in this memory area. And that’s an explicitly done operation.
So does the presence of Memoptimized Pool changes the way buffer cache works? Well, no and yes. No because database still stores the data blocks accessed from the disk, in the form of the buffers into the buffer cache if all what we have done is to allocate Memoptimized area. As already mentioned, buffers are going to be evicted from the buffer cache(and even from the Keep Cache) so eventually the buffers are going to be thrown out from the cache. Thus the buffers are always evicted out of the buffer cache as soon as they are entitled for it. Now, there is a CACHE clause which is around from ages but contrary to it’s name, it doesn’t really caches the buffers. All what it does is to give the incoming buffer a slight advantage in the buffer cache but eventually the buffer is still evicted, just like the buffers from those queries which didn’t use this CACHE hint.
Now, if we could pin our required buffers by some way in buffer cache, that would have given us surely some advantage in our query’s performance. But that pin mechanism doesn’t really exist for buffer cache, isn’t it?
And the last thing is how does the query actually gets to its data from the buffer cache? There are three Kernel layers of database that gets it done, mentioned below.
|
Execution Layer |
KX |
|
Access Layer |
KA |
|
Cache Layer |
KC |
Here KX layer handles the execution of the query. KA layer is going to access the database segments and finally KC layer which is going to manage the buffer cache and will manage the activity of IO , accessing the buffers so on and so forth.
Now, if by any means we can bypass this execution layer and basically go into the access layer directly, this should improve performance, as also mentioned in this whitepaper.
Note: Above mentioned three layers are not the only layers of the Oracle database kernel. There are quite a few left from being mentioned and described simply because they are not needed here.
Enter In Memory Hash index of Memoptimized Pool!
As mentioned already, memoptimized pool creates an in-memory hash index inside for the table(s) that is made part of the pool. This in-memory hash table is indexed with an index key that’s defined by the user. Now this looks like we are talking actually about a Hash Table and not a Hash index which is correct. Memoptimized Pool creates a Hash table only inside it but for some reason, that hash table is named as Hash Index in the documentation.
Given below is the way In-Memory hash index works.

So basically Hash Index maps keys of different rows of the table which is part of the Memoptimized Pool to the addresses of those rows in the cache of the Memoptimized Pool. So the data is now accessed via the Hash Index and then points to the buffers inside the Memoptimized Pool. To ensure that this data is not going to be thrown out, buffers are pinned into this memory area permanently.
Finally, doing all this, how does it helps? Since we are now have rows pointed in the cache from this in-memory hash index(table) structure, the IO for such rows will be using this Key-Value mechanism instead of using the standard logical IO aka consistent gets mechanism of the previous versions. Does that makes it faster? Yes. Since now you are directly jumping to access the data. Last but certainly not the least, doing all this doesn’t need any changes to either to your application code or to the tablespace holding the table.
All what you need is an ALTER TABLE command to make a table eligible to be a part of mem pool.
And this is what we shall be calling Fast Lookup.
In the next and final part, we shall see how we can use this feature in action. And we shall also look at Fast Ingest.
Hope it helped.
Aman….
Also see:


Recent Comments